First published on 2024-05-25.
Extended on 2024-06-30.
using obsidian
This is a short piece describing how I use Obsidian for organising my non-work-related data.
vault 1: organising my activities
It’s all about the setup. I have been struggling with note taking, lab communication, and document solutions for decades. Really. Far from having solved the second (but Slack is good in some cases) or third (but google suite or 365 do have merits in a few instances), at least now I feel solid on the first. And that already for a year. Let me explain.
My professional life consists of meetings and discussions. Many meetings are come-and-go: you talk about something which is only on the periphery of your interest, you try to put in your thoughts, and off to the next. One “meets” many people, often only once, but there is nothing close to a personal exchange.
And then there are meetings which have a topic, between 2 or 3 people, often face to face. These involve in-depth discussions, follow-ups, document, etc.
Finally, I try to do content work: write papers, run experiments, create initiatives, etc.
Finally? not finally at all. Since there is also a personal life. Family issues; sports; literature; arts; music. Perhaps it’d better been the other way around – those being work issues, and computer stuff personal – but that’s how it is.
And then I am a very procrastinating person. And someone who loves to start things, but is not so keen on finishing things. Ideally, I start something, and someone else picks up vault the leftovers and makes it into something nice. Yes, I drive life partners to insanity, and I apologise for that. Work partners are easier, since such a relationship can be defined from the beginning.
Enough of an intro. Let me explain to you how I try to have obsidian help me with this.
my daily notes
So to keep abreast of these many meetings, and knowing that you always meet twice, I need to jot down people’s names, the things we discussed, and so on. And on a good day I want to reread those notes to prepare for the next meeting. The intention is there, at least.
I tried notebooks and pens. I have a nice collection of ink pens with different colours I love. Orange, green, black – the ink, I mean. I like touching the pens, I love writing with them. But then… it is a bit like a brain-dump, albeit short and non-lasting. I have no good way of getting back to the notes. I tried doing daily summaries, recaps. I tried drawing todo checkboxes. I tried scanning and OCR, and even special OCR-included ink pens. But… well, if the search function is not perfect, it doesn’t work for me. The nice thing about paper notes is that they automatically get more distant as time progresses, and that aligns with the importance of a note. And that playing with colours and drawings is totally intuitive.
So following up on these ideas, I tried writing notes electronically. For instance in Notes; Goodnotes; Paper; Vittle; Sprite; all of these I tried writing in. Even tried Evernote. And then more. Goodnotes sticked the longest. Perhaps because I paid for it? And I still use it a bit, for the more art-centric stuff, quick drawings, and the like. But… for daily notes it completely failed for me. First since it’s bound to a device – it doesn’t work well on laptop, or on phone. It doesn’t have the advantage of paper (quick search; automatic forgetting). It gets messy. And… there is no search in hand-written text that works (for me).
And a major thing, I realised I really do not like to write with a plastic pen on a glass screen. I may be old-fashioned, but I’m used to that Coulomb friction; the immediateness; the permanence. (But miss the eraser; or is that a feature?)
I sadly had to turn back to the keyboard. I’m good with the keyboard, and aware of all the science showing that it’s not good enough for remembering what you did – but perhaps that’s fine for the types of notes I do. And then there’s lots of tools for this. Long-time Evernote user, I never used it for making daily notes. It’s too slow, to monstrous for that. And too often asks me for opinions. And rather than going through all other fails, let me conclude by saying that Logseq really did it for me. Because it is sleek, it opens up with that I need, it stores my files locally – so, I own my files, my data – and it is markdown-based.
Markdown advantage #1: it is normal text files with bells and whistles, which you can get by typing some special characters. Number 2: it is an open standard, not owned by one company, therefore persistent. #3: it just goes in local files. #4: it has an easy interface, rather than pressing a B button to go boldface, you can type in a simple command (two asterisks) to get it. And similar for many other commands.
So, Logseq can sync over my device sync mechanism, it runs on all my platforms, it is small, and it does what I want, with little requirements from my side to keep things neat. Problem solved, and I have been doing that for four years or so.
Still… it’s only daily notes. Going on to the second problem.
my life
As explained, my daily notes are only a part of my life. And indeed a small part, from a mental point of view.
Looking at what I’ve set up in Obsidian, my life consists of not more than 10 parts, and de facto only six:

The order is somewhat weird, I agree. The numbers are based on the Dewey decimal system. Remember libraries? Or ever been in one? There book spines often have this 3-digit number. That number is a topic categorisation, devised by Dewey, over a century ago. In my vault I didn’t follow Dewey’s classification, of course, since I am not a library; but I used the gist of it. The idea being, you can easily (and will automatically) memorise such numbers, and that allows you to find back topics and files in a directory. Yes, the above list correspond to directories on my file system.
In my taxonomy, sometimes the distinction between “science” and “work” is difficult. But for the rest, it’s been solid for a year now and works well for me.
Within each of the above I have subdirectories, of course. Sometimes neatly organised:

with a bit of useless playfulness with icons; and sometimes less so:

Works for me.
Note, at the top level, I have a directory called “daily”. It is, in fact, a copy of my Logseq notes, which are automatically synched both ways through git. More about my use of git later.
procrastination
The above makes a structure, which I need to maintain manually. The manual maintenance has a disadvantage – it can get messy – and an advantage – it requires attention and care, and therefore helps me memorising what’s what. So the theory, at least.
But the above does not solve my procrastination problem, nor the problem that I have too many loose ends. And for that I do something else.
Using the Linter plugin, I ensure that every file has a yaml header according to a template I set up. The least information there is creation date/time as well as last change. I want that to be almost automatic (not completely, since sometimes there are mini changes I do not want to have reflected – I was surprised my brain can get used to those differences).
In the yaml preamble, I also often have the tags: property. And here comes a second system I have. Underneath tags, each file can have one of four:
1-projects
2-activities
3-resources
4-archive
I did not devise this system; it is known as the PARA method which worked for me, once I had it adapted to my needs.
The idea is the following: “each” thing I do, collect, whatever, has one of these four labels. Tags. As follows:
- 1-projects is used for time-boxed projects. They have a real deadline, and a goal. Like writing a book, or finishing a review, or anything like that. Reading a book is less a project, unless it has a hard deadline and a specific goal.
- 2-activities are long-term things I work on. For me, it’s my running statistics, or keeping track of my literature list; it’s words I want to remember, and the like.
- 3-resources is a bit like 2-activities, but it is public information only. It is websites that I thought worth saving (through Omnivore); it is recipes; it’s a collection of links on how to maintain my coffee machine.
- 4-archive is that: anything from the above that is finished. Mostly from 1-projects and 2-activities, of course.
So a simple process: I create a Markdown file, I have Linter create it a yaml preamble; then I add one of the four above tags; and I put it either at root level or already integrated in the directory structure where I want it:
- putting it at root level will ensure I will easily find it back;
- giving it the correct tag will ensure I will easily find it back.
creating an index of files
And now comes in more power of Obsidian, through its plugins. Without the dataview plugin, obsidian would be lost for me.
Dataview is basically a tool to access the metadata (like the stuff in the yaml preamble) of your repository. And since it uses those data that are already prepared by obsidian, it’s fast.
I thus create an overview of my four categories:
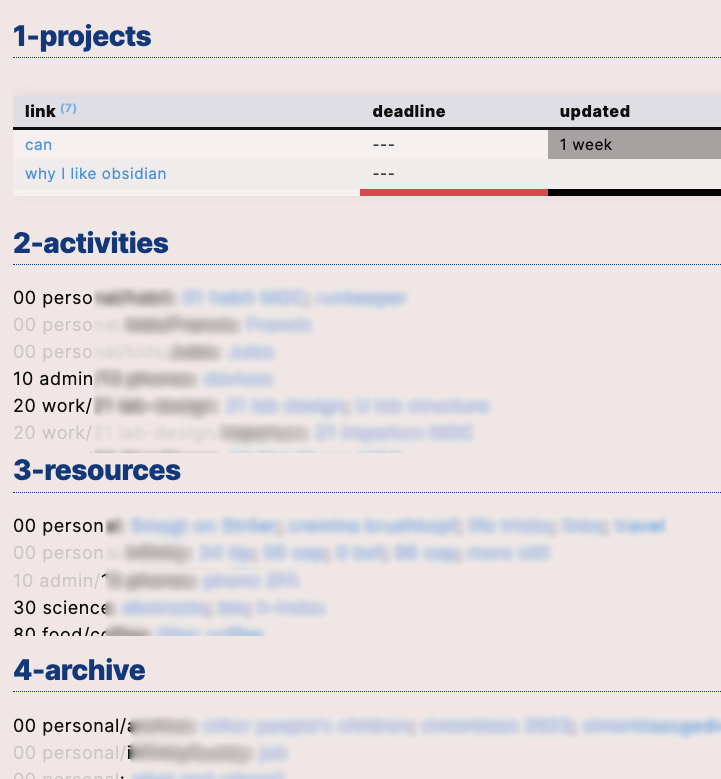
using somewhat involved Dataview/Javascript pieces of code. (The above picture is not real and complete. Sorry but… it’s only my business what’s in my notes!) I’m not ready yet to make this public, but contact me and I’ll share.
The look-and-feel of the whole is a key thing. On top, my deadline-based projects. (And you see I’m not consistent there, even; the top two are new but without a real deadline.) It lists the topics, sorts them by deadline, and shows a colour-coded reminder of how long I did not touch them. I typically have 5-ish projects in parallel, so this list is short.
Then the activities. This list is much longer, and ordered by category (read: directory). I make that list both compact and readable, with all marked files in a directory listed. It is a rather static list, of course, and typically the projects above are within those activities.
And then follows the same for resources, archive. The last is not so important, but sometimes I need to dig out something there. The resources, I mostly use it for finding recipes, book recommendations, and the like.
I have two different scripts for creating the above, of course. The first script for section 1, and the second script for all other sections. They run fast enough; even my 5-year-old phone needs less than a second to display this.
MOCs
And the third piece of structure is placed in Maps of Content or MOCs. While I do not completely consistently use them, they are often useful to set up a collection of more-or-less random notes, ideas, etc.
It works like this. Create this map file, and I like to add MOC to its name.
Then, dump lines in there with links to PDFs etc., notes, whatever. And then add the following dataview code:
list from [[]] and !outgoing([[]])
This piece of cryptic code does the following: it creates a list of all files which link to this MOC, but to which this MOC does not list. If I want them sorted in one way or another, I can just add a sort specification.
So you simply add a link to this MOC from a new Markdown file, and it gets included in the list of related-but-not-linked files.
git
OK, now things get a bit complex. Besides using obsidian sync, I like to use git to backup my data. The corresponding git plugin does it all for me.
But with two twists. First, I do collaborate on some of the contents. I share these contents via github, but of course I do not share my whole repo with these collaborators. For this I use git submodules, and once that is set up this is completely smooth and opaque. One caveat: renaming or even only moving a submodule is manual labour, and involves a few steps which, if you mess them up, creates git havoc. Naturally, I have a note in 10 admin/12 obsidian reminding me these 5 steps. Luckiyl, setting up a submodule is quite trivial with git submodule add git@github.com:...
Second: I use git to synchronise between Logseq and Obsidian. There are other ways, but this one works perfectly 999 out of 1000 times. (Sometimes I need to help solve some git hiccups, if I cause it to misbehave.) Basically, I just use again a submodule in Obsidian, and the normal Logseq git sync, to keep the two in agreement. It works both ways, but of course the sync is not instantaneous. That does not bother me.
One major use for this is keeping track of my habits. My sport, arts, and whatnot. For this, in Logseq I put entries like go:: 22:30, note the double double column. These are then easily parsable in Obsidian Dataview, and can be used to make graphs, plots, and such. Six of these, each with different output, are in my vault, and they create life plots like this:
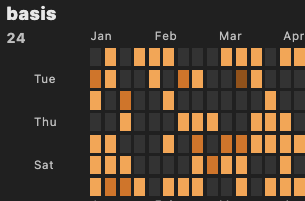
or this:

I’m not divulging what those plots indicate, but believe me, I use them frequently to congratulate myself on my progress. It helps me.
So, in my Obsidian git repo I have four subrepos: one for Logseq synchronisation; two for sharing files with other people, who also push/pull to the same repo. And one for synchonising LaTeX files with Overleaf. That goes indirectly, through an intermediate repo in github. The reason for that is that, unfortunately, the pro Overleaf version I use has no direct github integration, instead using its own git; so I use my computer to semi-automatically sync between the two sources (Obsidian and Overleaf) and keep everything up to date.
attachments
When synching with git repos, it is of course key that attachments that belong to a certain repo are also placed in that repo.
This means that, putting attachments in a global _resources directory does not work. In Options/Files and Links one can choose to have a local _resources (or whatever) directory where attachments are placed. That does not solve moving files though.
For this I use the Attachment Management plugin. I have set it up so that attachments always are in a local subdirectory, and that the attachment names are kept unchanged. It works stably.
canvases
Canvases are nice. But one problem: they do not have yaml stuff in there. So they don’t work with Dataview. And therefore, I don’t use them for anything serious.
tracking my papers
I have asked co-authors to help me in tracking paper writing. We set up various tools to do so, but each and every time people forgot, or deprioritised, and always I lost track of which paper was submitted, rejected, to be written, etc.
DIYS therefore. So now for each paper, I have a markdown file describing what’s going on as to that paper. This file has the following template:
---
tags: paper
firstauthor:
title:
source:
venue:
status:
---
MOC:: [[32 papers MOC]]
after which I use a bit of DataviewJS (see here) to create a table. It works beautifully.
plugins
- Activity History: a plugin that automatically tracks changes, and can be used to plot those. Looked nice when I started using it. But I never use those plots, which may look like this:
- Advanced Paste: allows for some more freedom in pasting text from, e.g., websites, or weird editors. I don’t use its powers often, but I use it.
- Advanced Tables: very useful (in fact, necessary) when you write a document in Markdown with a table.
- Attachment Management: moves my attachments with my notes, as explained in the git section above.
- Better word count: does a bit more on counting words in documents. Useful when writing a book, for instance. Especially on mobile devices, the native Obsidian word count is not enough.
- Book search: saves me a lot of time when writing my book reviews. It does web searches on book titles and then extracts the book metadata into yaml.
- Calendar: I don’t really use it much, but it displays a small calendar, which is linked to my Logseq files. Works.
- Charts: makes the above charts.
- Colored tags: does what it says. I should get rid of this.
- Commander: adapts the workspace by allowing you to change the which commands are where. I think I used it once, then forgot about it. Probably I should not remove it.
- Custom file explorer sorting: now this may sound silly, but I searched for a plugin doing this and am happy I found it. It allows me to sort directories differently, and in my case that means, reverse order. I use it in my Logseq list of files. When I want to edit the last file (i.e., something from today or yesterday) in Obsidian, before I’d have to scroll through years of notes, one file per day. This reverse sort solves that trivially. But come to think of it, I could also have used the Calendar plugin above.
- Dataview: the one plugin without which Obsidian would be just any other note taking tool for me.
- Editor syntax highlight: does that, for code blocks in md files. I have code blocks, and it’s nice for that.
- Enveloppe: for publishing this blog from obsidian. Works after extreme hand tuning. I explain elsewhere how I did that.
- Excalidraw: just that. For drawing. I don’t use it much, but do. The one plugin with the most frequent updates.
- Find orphaned files and broken links: it does that, and well enough. Auto-deleting plugins exist as well but don’t work for me, as not every file in my vault is referenced to. I run this manually, infrequently, when I’m bored.
- Force note view mode: it uses yaml frontmatter to allow you to specify if a file is to be shown in view rather than edit mode, by default. I use it for my dashboard. Can’t really do well without this plugin.
- Frontmatter tag suggest: I never remember if it’s called
1-projectsor something else; but I remember the1-. This plugin then auto-completes. Perfect. - Fullscreen mode plugin: good when I’m writing.
- Git: explained above.
- Heatmap calendar: makes those heatmaps I showed above.
- Hide sidebars on window resize: does what it says, for small screens.
- Homepage: displays my Dashboard, always.
- Iconize: allows me to add the icons, shown above. Nothing more than a gimmick for me.
- Linter: does auto-formatting, and keeps the last-update-time in yaml up to date. There are also special plugins for this, but why use those if Linter does it for me.
- Mermaid tools: creates diagrams. I used it once.
- Natural Language Dates: allows you to write things like
@todayand so. Sounds nice, but I never use it. - Number Headings: allows for automated section numbering, based on your preferences in the file’s yaml. Sometimes useful.
- Omnivore: A very nice integration with the Omnivore tool, to get websites or emails in your Obsidian vault. Omnivore is, of course, amazing, and what’s their business model again? I hope it lives long.
- Plugin Update Tracker: tracks which plugins have updated, and gives you discreet hints about that. Since there is no automated plugin update mechanism in Obsidian, this one is quite useful and keeps my mind off having to think about checking for updates.
- Recent Files: maintains a longer list of recently accessed files than Obsidian does. I used it, then discarded it.
- Settings Search: searches… settings. Hardly ever use it, but I do.
- Spaced Repetition: a flashcard plugin.
- Style Settings: allows for including CSS. I need that for making my Dashboard work, and I need it to write long texts in a distraction-free environment.
- Templater: creates templates which you can use to more consistently create new types of files. Looks nice, but I don’t use it anymore.
- Text Generator: uses your favourite LLM API to generate text. Works quite well, but I hardly ever use it.
- VSCode Editor: allows me to edit code files with a bit of syntax highlighting, etc.
That’s a lot, I know, and the startup time for these plugins is about 1.5s. Most of the time is used for Excalidraw, about 350ms; next in line is Text generator with about 300ms. Disabling these much speeds up start time, if I need that – and I do that on my mobile devices where I cannot have two vaults open at the same time, instead need to switch between one and the other where needed.
I also miss some plugins, and will perhaps one day write these myself. First, I miss a plugin to do LaTeX editing. Yes, of course I can edit the files, because of the VSCode Editor plugin. But that does no syntax highlighting (which I don’t need, but…) or any other support to make that editing comfortable.
Second, more important, is the integration with Logseq todo’s. In an evil step, Logseq moved away from standard Markdown todo syntax, and extending it so as to allow for measuring times, keeping todo/doing/done lists, etc. These are nice extensions, but I cannot use the resulting todos in Obsidian.
My only way out, currently, is to use the following query:
```query
match-case:("NOW") path:"daily/journals" -path:"daily/journals/logseq"
It at least lists them, but not as todos. It’s not nice.
settings
A few important settings for my setup. In Options/File and Links I make Obsidian detect all file types. This is needed for the VSCode Editor plugin.
In Appearance, apart from having chosen a different look, I have activated a number of css files. Some of these are required for my Dashboard to work (remember the grey look of repeated directories? Or the grey, pink, red background of cells? All because of a bunch of css files. Then, my MOCs have a different look. And the books I write in Obsidian, to minimise distraction and optimise readability.
Most important for me, in the Sync settings, I sync everything except for the list of active core and active community plugins. Some plugins I do not want active on some mobile devices, to save time (e.g. the Excalidraw plugin), space, or chaos (e.g. the git plugin).
Obsidian services
And then, essentially, I use Obsidian sync. It works very, very stably, and close-to-fast-enough. No, not fast enough; I sometimes enjoy watching the files come in for a few seconds– on my mobile devices. Luckily there’s an interface for that. But it’s fine.
I started off with my ecosystem sync mechanism, and it’s erroneous.
vault 2: my documents
That’s not all though. I have a second vault.
This second vault I use to carry my digital documents around. Invoices, insurance documents, registration forms, travel itineraries… any of that stuff that is, used to be, basically paper based.
So it’s mostly PDFs and such. Many of those which I received digitally, but many others which I received in paper form.
For about a decade I used Evernote to keep these. Especially the OCR in Evernote, which allowed me to search in scanned PDFs, did it for me.
But after years of Evernote use, I got increasingly dissatisfied with the increasingly archaic interface – the rest of the world improved, but they did not – its sluggishness, and the tendency of the company to make their subscription approaches increasingly complex. I tried to go to OneNote. I tried Bear, with its beautiful interface (but no PDF scanning) and Markdown.
And then I discovered Obsidian.
Learning from how to organise my data in Evernote for many years, and knowing that that did tend to end up in a mess, I decided to make this dedicated, short-memory, and singular.
Singular meaning, mostly I (now) have one Markdown file, with one attachment, for most cases.
Dedicated meaning, these attachments are, basically, those paper documents which, in another era, one would put in a folder and sort those by category,
And short-memory meaning, those documents that are not needed forever end up in annual folders. Documents which do have timeless information end up in one of the following: work; music; food; cabinet; bank. The cabinet one is really permanent stuff. It’s the largest of the directories. Food: recipes. Music: scores. Work: paperwork about my work, not containing my work. Etc.
So this is a very static repository. I do not write anything here. Things are scanned, transferred to Obsidian (my scanner uploads to Dropbox; my computer has a folder action and, upon a new file appearing, moves it to my top folder in this vault and puts a Markdown file around it). Then I manually annotate it, where needed (yes, this could be done with some LLM action). And sort it in the right directory.
Why the manual sorting? Well, since some things I want to have disappear. Like invoices of things that are only important for tax returns. So I have folders 2018, 2019, 2020, 2021, 2022, 2023, 2024, and 2018 is going to be deleted soon.
- Attachment Management: as above, this one is set up to move the attachment with the markdown file. I also set it up to have the attachments renamed, same as the markdown file. This allows me to keep markdown and attachments close together, and get a clean repo.
- Find orphaned and broken links:…but even then, sometimes attachments roam around unattended. Sometimes I check this.
- Git: to create a persistent backup. Details below.
- Omnisearch: the search engine that replaces that search functionality I loved so much in Evernote.
- Quick tagger: bulk change of tags. Don’t use it much, but I do.
- Tag wrangler: more search and edit actions for tags.
- Text extractor: needed for omnisearch, for scanning PDFs or images which do not have text.
- Trash explorer: a better way to find back files I deleted.
- Update time on edit: updates the edit times of markdown files automatically. While in the other vault I do this on explicit saving, here it’s on every minor update.
Now it looks as if I use tags consistently. But I do not, I am too messy to do that. I won’t give up trying yet, because for some things the tags are very useful – it is, for instance, my solution to gathering tax return information. By giving each file the corresponding tag, this has become a fast process.
git
My git setup here is different, for the very simple reason that this vault contains some personal data. My git repo is mine and mine only, but still, git does not encrypt so it’d be out there in cleartext.
To solve this, I use git-crypt with gpg. This can be made completely transparent by adapting your .gitattributes and .git/config files. Downside: encryption is done per-file, so the names of the files are still in cleartext. And of course, git uploads binary files and thus loses efficiency. My files are small enough so that is not an issue.
final
If, like me, you came from Evernote, you can use yarle-evernote-to-md.app.
And a final thing: the text search in image-based PDFs doesn’t work very well, sadly. It appears that the text extractor plugin does not work on all PDFs. A newer plugin, called OCR, is promising but buggy as I write this. A tool like https://docs.paperless-ngx.com is probably more powerful than my approach. But I do not like to put my documents on a server owned by someone else, especially when my data are not encrypted.
Table of contents
- Adichie, Chimamanda Ngozi: Half of a Yellow Sun
- Adiga, Aravind: The White Tiger
- Anderson, Gillian: Want
- Applebaum, Anne: Autocracy, Inc.
- Atsuhiro Yoshida: Goodnight Tokyo
- Atwood, Margaret: My Evil Mother
- Atwood, Margaret: Surfacing
- Atwood, Margaret: The Handmaid's Tale
- Atwood, Margaret: The Testaments
- Auster, Paul: Baumgartner
- Auster, Paul: Invisible
- Auster, Paul: Oracle Night
- Auster, Paul: The Brooklyn Follies
- Auster, Paul: Moon Palace
- Auster, Paul: The Music of Chance
- Auster, Paul: Winter Journal
- Barker, Pat: The Silence of the Girls
- Barker, Pat: The Voyage Home
- Barker, Pat: The Women of Troy
- Barnes, Julian: England, England
- Barry, Sebastian: Old God's Time
- Birmingham, Kevin: The Sinner and the Saint
- Boyd, William: The Romantic
- Brandt Corstius, Jelle: Arctisch dagboek
- Brodesser-Akner, Taffy: Long Island Compromise
- Burns, Anna: Milkman
- Buruma, Ian: Inventing Japan
- Buruma, Ian: The collaborators
- Caldwell, Lucy: The Meeting Point
- Calidas, Tamsin: I Am An Island
- Cisneros, Sandra: The House on Mango Street
- Clarke, Susanna: Jonathan Strange and Mr. Norrell
- Clarke, Susanna: Piranesi
- Cline, Emma: The Guest
- Cohen, Joshua: The Netanyahus
- Collins, Wilkie: The Moonstone
- Crumey, Andrew: Beethoven's Assassins
- Crystal, David: Making Sense
- Crystal, David: Making a Point
- Crystal, David: Spell it out
- Crystal, David: The Gift of the Gab
- Crystal, David: The Story of English in 100 Words
- Cummins, Jeanine: American Dirt
- Dangarembga, Tsitsi: Nervous Conditions
- Dangarembga, Tsitsi: The Book of Not
- Dawson, Jill: The Bewitching
- Diamond, Jared M.: Guns, Germs and Steel
- Diaz, Hernan: Trust
- Doerr, Anthony: All the Light We Cannot See
- Dolan, Naoise: The Happy Couple
- Dostoyevsky, Fyodor: Crime and Punishment
- Edugyan, Esi: Washington Black
- Enright, Anne: The Wren, the Wren
- Ericsson, Anders: Peak
- Ernaux, Annie: Getting Lost
- Everett, Percival: Dr. No
- Ezemi, Akwaeke: You Made a Fool of Death with Your Beauty
- Feeney, Elaine: How to Build a Boat
- Feynman, Richard: Surely You're Joking, Mr. Feynman!
- Frank, Anne: Het Achterhuis
- Fridlund, Emily: History of Wolves
- Galchen, Rivka: Everyone Knows Your Mother Is a Witch
- Gogol, Nikolai: The Nose
- Golden, Arthur: Memoirs of a Geisha
- Gran, Sara: The Book of the Most Precious Substance
- Groff, Lauren: Matrix
- Gurnah, Abdulrazak: Afterlives
- Hammett, Dashiell: The Maltese Falcon
- Hjorth, Vigdis: If Only
- Ho Davies, Peter: A Lie Someone Told You About Yourself
- Homer: The Odyssey
- Hosseini, Khaled: A Thousand Splendid Suns
- James, E. L.: Fifty Shades of Grey
- James, Henry: Daisy Miller
- James, Henry: The Turn of the Screw
- Jokha, Alharthi: Celestial Bodies
- Joyce, James: Ulysses
- Jünger, Ernst: In Stahlgewittern
- Kadare, Ismail: The Doll
- Kadare, Ismail: A Dictator Calls
- Kawaguchi, Toshikazu: Before the Coffee Gets Cold
- Kawakami, Hiromi: The Ten Loves of Mr Nishino
- Keer, Jenni: No. 23 Burlington Square
- Khromeychuk, Oleysa: The Death of a Soldier Told by His Sister
- Kidd, Jess: The Night Ship
- Kim, David Hoon: Paris Is a Party, Paris Is a Ghost
- Kitamura, Katie: Intimacies
- Lacey, Catherine: Biography of X
- Lahiri, Jhumpa: Whereabouts
- Lee, Harper: To kill a mockingbird
- Leilani, Raven: Luster
- Lianke, Yan: Hard Like Water
- Lister, Kate: A Curious History of Sex
- Mackintosh, Sophie: Cursed Bread
- Mallo, Agustín Fernández: Nocilla Trilogy
- Mark Manson: The Subtle Art of Not Giving a F*CK
- Masuda, Sayo: Autobiography of a Geisha
- Matsumoto, Seicho: Tokyo Express
- McCann, Graham: A Very Courageous Decision
- McGuire, Ian: The North Water
- Melchor, Fernanda: Hurricane Season
- Mendelson, Charlotte: The Exhibitionist
- Mitchell, David: The Thousand Autumns of Jacob de Zoet
- Mohsin Hamid: Exit West
- Murata, Kiyoko: A Woman of Pleasure
- Murata, Sayaka: Convenience Store Woman
- Murata, Sayaka: Earthlings
- Nabokov, Vladimir: Laughter in the Dark
- Nabokov, Vladimir: Lolita
- Nabokov, Vladimir: The Enchanter
- Navalny, Alexei: Patriot
- Neill, Alexander Sutherland: The Last Man Alive
- O'Farrell, Maggie: Hamnet
- Oyamada, Hiroko: The Factory
- Ozeki, Ruth: A Tale for the Time Being
- Patchett, Ann: Bel Canto
- Patchett, Ann: The Dutch House
- Pearson, Laura: The Last List of Mabel Beaumont
- Perre, Selma van de: My Name Is Selma
- Porter, Max: Grief Is the Thing with Feathers
- Power, Chris: A Lonely Man
- Powers, Richard: The Overstory: A Novel
- Proulx, Annie: The Shipping News
- Rijneveld, Marieke Lucas: Mijn lieve gunsteling
- Rijneveld, Marieke Lucas: De avond is ongemak
- Riley, Gwendoline: My Phantoms
- Rooney, Sally: Beautiful World, Where Are You
- Rooney, Sally: Normal People
- Rubin, Gretchen: Forty Ways to Look at Winston Churchill
- Schrödinger, Erwin: What Is Life?
- Shafak, Elif: 10 Minutes 38 Seconds in This Strange World
- Smiley, Jane: A Dangerous Business
- Stockett, Kathryn: The Help
- Stuart, Douglas: Shuggie Bain
- Stuart, Douglas: Young Mungo
- Taddeo, Lisa: Animal
- Taddeo, Lisa: Three Women
- Teich, Jack: Operation Jacknap
- Thayil, Jeet: Low
- Tóibín, Colm: Brooklyn
- Whitehead, Colson: The Nickel Boys
- Whitehead, Colson: The Underground Railroad
- Wilde, Oscar: Lord Arthur Savile's Crime and Other Stories
- Wolf, Naomi: Vagina
- Wood, Benjamin: The Young Accomplice
- Yagisawa, Satoshi: Days at the Morisaki Bookshop
- Yoder, Rachel: Nightbitch
- Yokoyama, Hideo: The North Light
- Yuzuki, Asako: Butter
- About
- books I've read
- how I made this blog
- how I use Obsidian
- readable paper writing